S3 Data Load into Snowflake
This document details the process to integrate data from a S3 bucket location to a Snowflake console
Data Retrieval Process
-
Specify the warehouse we're retrieving from through a compute function
-
You may need to create the warehouse before accessing it by adding it to your snowflake account or the command
CREATE WAREHOUSE [WAREHOUSE NAME] -
USE WAREHOUSE COMPUTE_WH

-
-
Create the database schema if it does not already exist
-
A schema describes how data is organized in a relational database, like a blueprint. In this instance we're referring to logical database schema, and so we are defining the database name and outline.
-
Although a table outline is also a schema, we use the
schemacommand to set up our database and thetablecommand to create the schema outline -
e.g. [DB name].[DB name]_raw_data

-
-
Create a Snowflake table with a matching schema to the parquet file
- Define the column name and type with actual name and type from parquet file
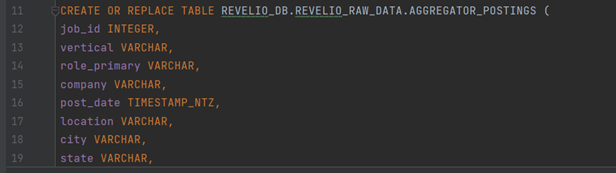
-
Create a Snowflake stage to reference the S3 bucket
-
A Snowflake stage object is a reference to a storage location to aid the unloading of data.
-
Your AWS security key credentials will be needed
-
Set the URL to the S3 bucket location you're retrieving from
-
Set the Credentials to your AWS Key ID & Secret Key

-
-
Copy the data from the created stage into the Snowflake table
